Methodology
The data collected is based on patent applications filed with single or joint ownership of Italian Public Research Institutes and Bodies. The rigor of choice with respect to the quality of the information collected suffers from two limits, known well to those who are in this field, are the reliability with regards to the timeliness of information caused by delays in the registration procedures and disregarding patents owned by different subjects (institutions), but which include a professor or university researcher as an inventor. The first aspect is an unavoidable feature linked to patent data. The second involves solving very specific technical problems of combining information relating to inventors and their professional characterizations.
The topics of discussion related to patenting in public institutions are many and have for some time been the subject of the attention of scholars from various disciplines, private operators and public decision makers. This project does not address any of these issues, but focuses on the goal of providing everyone with the database necessary to support these studies and discussions in an informed and updated manner.
Based on the experience acquired in the management of the Patiris web service, online since 2013, on the suggestions received from active users and taking into account potential synergies and complementarities with respect to the services offered by commercial operators, the main alternatives were evaluated and finally the data from the Open Patent Services (OPS) platform provided by the European Patent Office (EPO) was selected.
OPS is a web service that provides access to raw EPO data via a standardized XML interface. The OPS patent data is extracted from the EPO databases which, in addition to bibliographic data, gives also access to information regarding the legal status of the patent, full-text documents and images. All information comes from the same data sources as Espacenet and the European Patent Register (EPR).
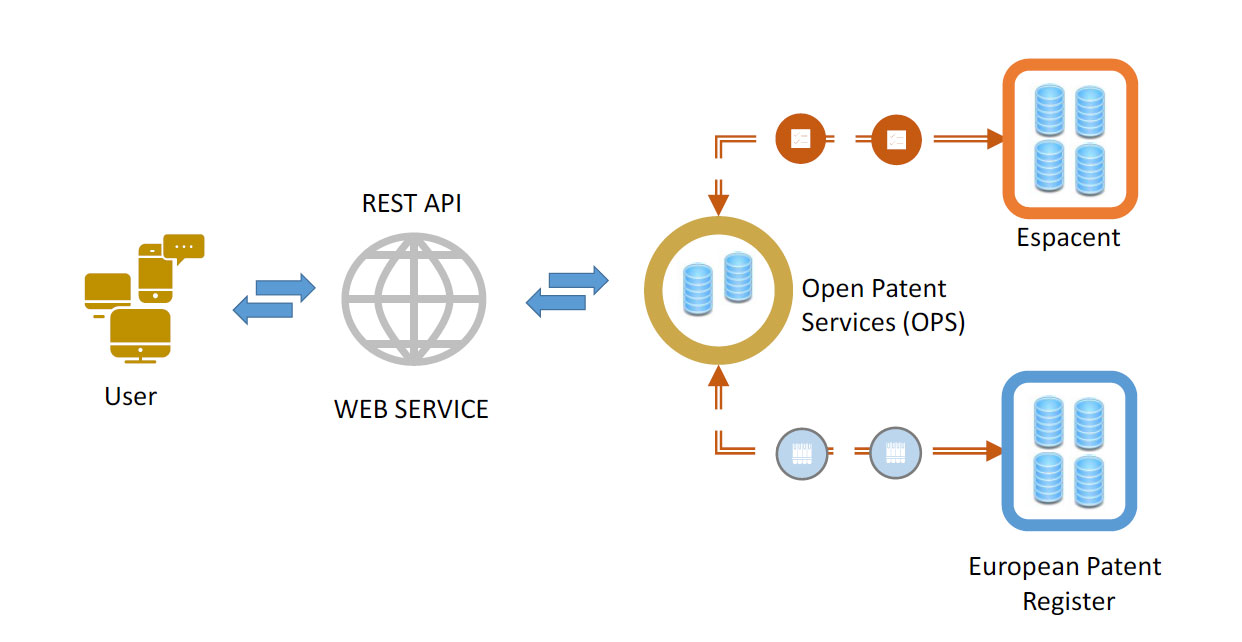
The EPR data contains all the information relating to the different phases of the patent granting process and the complete historical data for each individual European patent application at any given time. This does not only include the information listed in "Rule 143" of the EPC (e.g., number of the European patent application; the filing date of the application; the title of the invention; the classification assigned; the designated states etc.) but also additional data such as legal status, details of the legal representative, etc.
Espacenet is probably the most comprehensive patent document search tool available for free, globally. It is developed and supplied by the EPO and today contains more than 120 million patents from over 100 countries dating back to 1836. Furthermore, in Espacenet, further data relating to the legal status of the patent, any citations and related patent families (Simple and INPADOC family) associated with the application are also provided.
Patent Family
The term patent family generally refers to a group of patent documents which, like a family, are linked together. The link is represented by a common priority. The priority date and the relative priority number indicated on all patent documents indicate the date from which the novelty of an invention is claimed and the rights also apply to applications filed subsequently. Generally, the priority date corresponds to the first filing date in the applicant's country. Documents belonging to the same family are called “equivalent” and have one or more priority numbers in common.
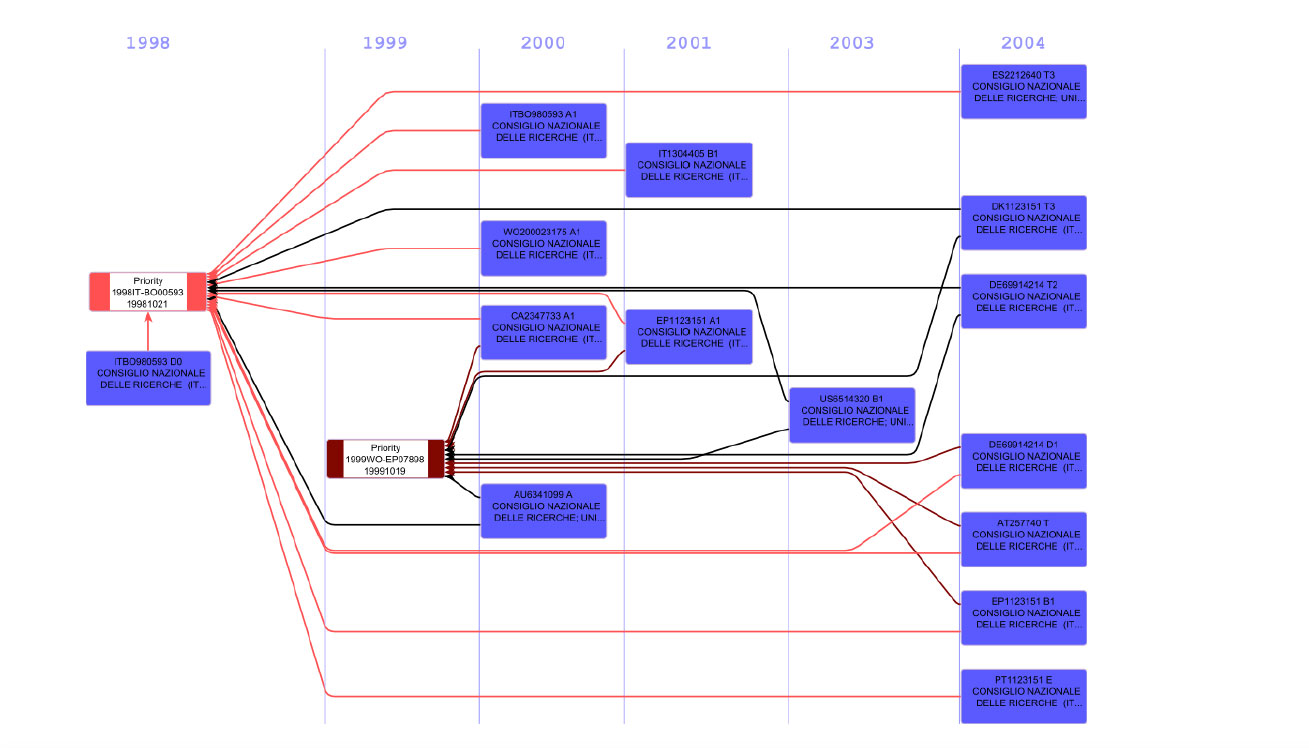
Therefore, the set of patents that make up a family are represented by a number of documents that refer to the same priority number. This means that despite the same invention being subjected to different legal procedures depending on the countries in which the patent application was filed, from the point of view of evaluating the innovative performance, all the documents of a family identify as a common research product.
In the case of EPO and PCT (Patent Cooperation Treaty) procedures, for example, a single patent application makes it possible to cascade a plurality of patent documents in order to protect the underlying invention in multiple states without having to repeat, state by state, all the individual procedures of question.
There are different types of patent families distinguished by the criterion used to group individual patent documents. The use of each type of family has pros and cons depending on the type of analysis carried out. All of these aspects make the research and analysis of patent information complex and particularly influenced by the subjective choices of the analyst.
EPO Family
The INPADOC family comprises all documents that have the same priority or combination of priorities. This includes all patent documents arising from a patent application filed as a first filing with a patent office and from the same patent application filed within the priority year at any patent office in another country. This type of family is particularly useful for carrying out prior art and legal status analysis as it allows to find all members of a family who are even remotely connected, but it can be too large to handle for the purposes of Patiris (to identify single inventions), as it could make it difficult to find the exact relationship of a single patent document to another.
On the other hand, the EPO family or simple family, which corresponds to the definition used in this project, strictly speaking stipulates that, two documents can be considered equivalent if they all share the same priority; therefore, a simple family turns out to be a collection of patent documents which are believed to cover a single invention and the technical content of the different applications contained in the family is considered identical. This is a very precise and accurate type of grouping by invention for analysis strategies aimed at identifying prior art.
Derwent Family
The “Derwent” patent families, which can be consulted through the Thomson Reuters Derwent World Patent Index (DWPI) database, are generated through an expert coding process. Thomson Reuters uses experts with expertise developed over 40 years to create patent families whose members have similar technical content.
FamPat Family
The "FamPat" family, developed by Questel and used in the previous version of Patiris, expands the rigid rule of the EPO family with additional rules so as to incorporate variations in the definition of invention from different patent authorities (particularly useful for searching for Japanese publications and Americans). The FamPat family and database combine all the steps of publishing member documents together. Searches by assignee, inventor or classes are refined on all family equivalents. The IDs assigned to each family are stable over time.
IP5 OECD Family
To better reflect the inventive activity that the best corporate R&D performers carry out around the world, OECD introduced in 2015 a new definition of a patent family, the IP5 patent families which are based on patent applications filed with the IP5: EPO, JPO, KIPO, SIPO and USPTO. IP5 is the name given to a forum of the five largest intellectual property offices in the world, established to improve the efficiency of the patent examination process around the world; together they handle approximately 80% of world patent applications and 95% of all international patent applications for PCT (http://www.fiveipoffices.org/). The definition of IP5 patent families is as follows: patent families are taken into consideration only to the extent that equivalent applications have been filed in at least two offices where one is an IP5. For example, patents filed with the USPTO will only be considered if an equivalent filing has been made in any other patent office in the world..
Institutes and Public Research Bodies
The main objective of Patiris is to identify all the patent families that have an Italian university or Public Research Institute as their assignee, with the aim of building periodic reports on academic patenting. For this purpose, a registry of the monitored institutions has been defined which is based on the information provided by the Ministero dell'Università e della Ricerca. The definitive database contains 98 Universities, 20 Public Research Bodies listed in Article 1 of the LEGISLATIVE DECREE 25 November 2016, n. 218 with the addition of the " Fondazione Istituto Italiano di Tecnologia ", controlled not only by MIUR but also by other ministries, for a total of 119 institutes.
Starting from the names of the institutes, numerous incremental cycles of research and refinement of text strings were carried out for each, with the aim of determining groups of optimal search strings and identifying the possible name variations observable within patent documents.
This activity, essential to allow stable and coherent research over time, was necessary because there is no univocal code assigned to the institutes by the various international authorities. On the contrary, from time to time, the institutions that appear as assignees are identified (e.g., at the time of application) only by their name and other information (e.g., address) encoded in the form of text strings. Consequently, in carrying out searches based on the name of the assignee, obvious problems of ambiguity relating to the different names of the same institution that are indicated over the years on patent documents must necessarily be resolved.
In fact, due to data entry errors, variations of the same name or artifacts generated during the digitization process of paper documents using OCR technology, were encountered, where multiple variants of the same name corresponded to the same institution. To overcome this issue, it is necessary to build increasingly complex search strings by trial and error in order to capture the variety of names present in the stock of patent documents to be observed. Without searching with Boolean operators to link the possible variants, it would be impossible to correctly identify all potentially relevant documents and / or families of documents.
System architecture and database population
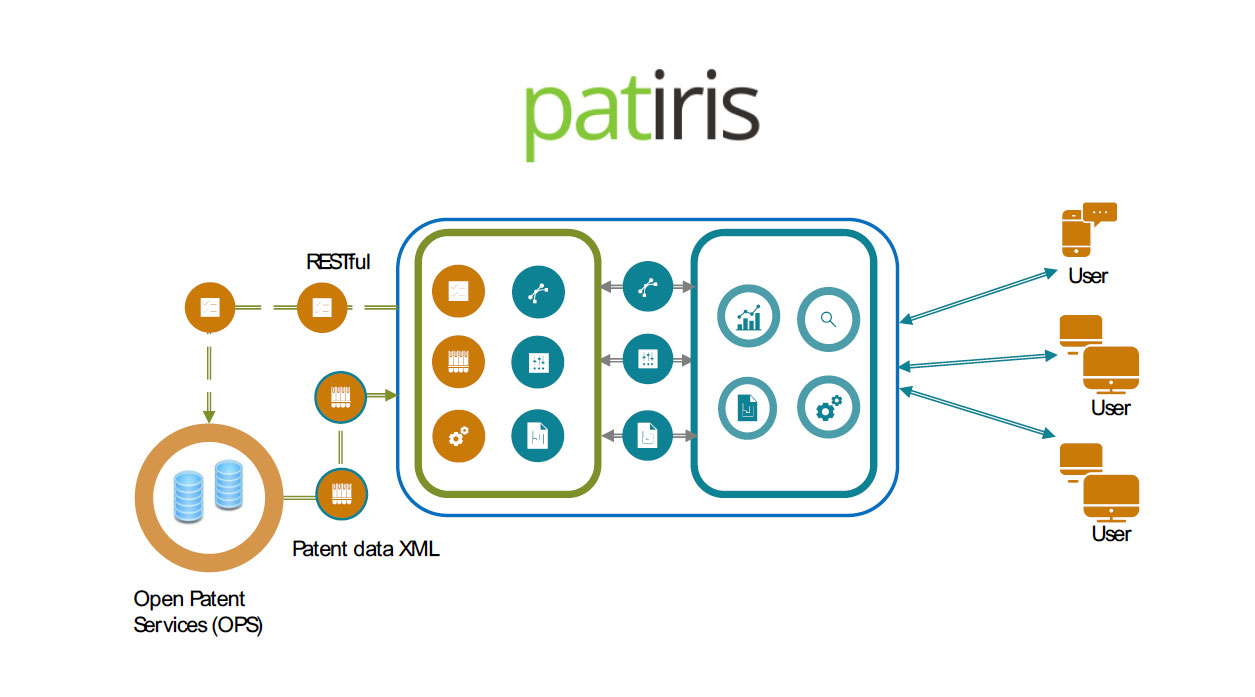
As mentioned previously, EPO's OPS is the source from which the data for Patiris is extrapolated. Starting from the disambiguation of the names of the institutes, queries are initially generated to search for all the patents relating to the indicated institute. Once the first data has been obtained, a second search is performed based on the patents and families acquired in the first phase, to search for all the patents belonging to the same analysed family, the so-called “equivalents”. The OPS service provided by EPO provides highly performing search functions including the search for all the patents of the same family starting from the knowledge of a single patent pertaining to that family. This allows to obtain exhaustive and complete data capable of satisfying the requirements and objectives of the restructuring of the Patiris platform. Once the information has been extracted from the EPO database, all data is normalized and organized to populate PATIRIS.